


У 2026 році e-commerce бренди конкурують не лише за позиції в Google, а і за місце в джерелах, які читають AI-системи. Якщо про бренд немає нейтральної публічної source base у Wikipedia, Wikidata, Reddit, Quora і незалежних медіа, AI може його не побачити, переплутати або описати через випадкові старі сигнали.
Редакторка Tovar.media Ірина Маслова поспілкувалася зі співзасновником WikiBusines Богданом Дубильовським про те, як компаніям, засновникам бізнесу, агенціям та публічним особам створювати надійну присутність у Wikipedia, Wikidata, Reddit, Quora та інших платформах, які цитують AI-системи.

Богдан Дубильовський
Розкажіть коротко про вашу компанію – які болі підприємців ви закриваєте?
WikiBusines будує для бізнесу публічну інфраструктуру довіри: присутність у джерелах, які читають не лише люди, а й AI-системи. Це Wikipedia, Wikidata, Reddit, Quora, Google Knowledge Graph, AI-відповіді та інші майданчики, де бренд або існує як перевірена сутність, або губиться в шумі.
Ми працюємо з 2010 року, створюємо понад 1,000 Wikipedia-сторінок на рік, робимо понад 5,000 редагувань і покриваємо 160+ мовних розділів. Але суть не в «сторінці у Вікіпедії». Суть у тому, що покупець дедалі частіше не йде на сайт компанії. Він питає ChatGPT, Gemini, Perplexity або Google AI Overview: «кому можна довіряти?», «який сервіс обрати?», «чи ця компанія легітимна?». І відповідь формується не з банера на сайті, а з незалежних джерел.
Ми називаємо це Trust Visibility Infrastructure. У неї три шари. Перший – Foundation: незалежні медіа, галузеві звіти, нагороди, регуляторні документи, реальні докази. Другий – Anchor: Wikipedia, Wikidata, Simple English Wikipedia, тобто канонічне й машиночитане представлення компанії. Третій – Surfaces: Google Knowledge Panel, ChatGPT / Gemini / Perplexity, Reddit, Quora, LinkedIn – місця, де бренд спливає перед покупцем і перед AI.
Підприємці приходять із трьома типовими болями. Перший: «нас не видно там, де тепер перевіряють довіру». Другий: «AI описує нас неправильно або взагалі рекомендує конкурентів». Третій: «ми пробували самі, але Wikipedia видалила сторінку, а Reddit забанив пост».
Наша робота – не обдурити алгоритм, а зібрати таку джерельну базу, яка витримує і редакторську перевірку, і AI-retrieval. Якщо база не тримається, ми чесно кажемо це на source assessment. На проєктах, які беремо після аудиту, маємо близько 93% успішних публікацій.
Для класичного ритейлу Reddit довго здавався майданчиком для геймерів чи гіків. Чому зараз e-commerce брендам критично важливо мати там слід?
Тому що Reddit став місцем, де покупець звіряє рекламну обіцянку з реальністю. У e-commerce майже все виглядає як реклама: сайт хвалить бренд, SEO-огляди часто affiliate-driven, маркетплейсні відгуки викликають підозру. А на Reddit питають грубі, практичні речі: «що реально не зламалося через півроку?», «у кого підтримка не зникає після оплати?», «який матрац не перетворюється на болотце за три місяці?», «яку CRM не зненавидить операційна команда?»
Reddit уже сам позиціонує себе як shopping-платформу. У 2026 році компанія повідомляла про 40% річного зростання high-intent shopping conversations, а 84% shoppers на Reddit відчувають більше впевненості після дослідження продукту на платформі. Це не дрібниця: для дорогих або порівняльних категорій – меблі, техніка, косметика, CRM, логістика, fintech, дитячі товари, медичні продукти – Reddit стає не «додатковим каналом», а кімнатою, де покупець радиться перед оплатою.
Цінність Reddit не в тому, щоб «купити пост». Це майже завжди шлях до бану й репутаційної пожежі. Цінність у peer consensus – живій думці спільноти. Саме її потім читають інші покупці, Google і AI-системи.
Як великі мовні моделі використовують Reddit, коли відповідають на запити на кшталт «яка найкраща CRM для інтернет-магазину?»
Є три механіки.
Перша – доступ до даних. У 2024 році OpenAI та Reddit оголосили партнерство: OpenAI отримала доступ до Reddit Data API, щоб ChatGPT краще розумів і показував Reddit-контент, особливо щодо актуальних тем. Google також отримав доступ до Reddit Data API в межах розширеного партнерства, яке ринок оцінював приблизно у $60 млн на рік.
Друга – retrieval. ChatGPT Search, Google AI Overviews, AI Mode, Perplexity та інші answer engines не просто «пам’ятають інтернет». Вони шукають джерела під конкретний запит: порівняння, форуми, Wikipedia/Wikidata, Quora, Reddit-треди, огляди, профільні медіа. Для питання «best CRM for Shopify store» сайт CRM-провайдера – це лише self-published claim. А дискусія, де реальні власники магазинів сперечаються про Shopify, HubSpot, Zoho, Klaviyo чи Odoo, – це вже сигнал досвіду.
Третя – authority і цитування. Різні дослідження AI-citations показують, що Wikipedia і Reddit стабільно серед найбільш цитованих доменів, але частка сильно залежить від типу запиту й моделі. Тому важливо не ловити одну «магічну цифру», а будувати source density: щоб про бренд були незалежні джерела, структуровані дані й живі обговорення.
Щодо Claude треба бути точними: публічно підтвердженого партнерства Anthropic із Reddit рівня OpenAI чи Google немає. Але Claude, як і інші системи, може використовувати знання з навчального корпусу, веб-пошук у відповідних режимах або джерела, що вже переказали Reddit-дискусії.
«Vibe check» від ШІ: якщо бренд має бездоганний сайт, але на Reddit три роки тому написали негативний відгук, як це вплине на відповідь ChatGPT?
Один старий негативний відгук не знищить репутацію автоматично. Але якщо це один із небагатьох незалежних сигналів про бренд, він звучить непропорційно голосно. Для AI ідеальний сайт компанії – це self-published marketing. Reddit-тред – це peer discussion. І часто модель більше довіряє не блискучій вітрині, а брудному сліду черевиків біля каси: там, де люди сперечаються, скаржаться, радять, виправляють одне одного.
Тут працює принцип source density. Якщо про бренд є тільки сайт і один негативний тред, негатив стає центром гравітації. Якщо є Wikipedia/Wikidata, незалежні медіа, свіжі Reddit/Quora-дискусії, галузеві огляди, structured data – старий негатив стає одним елементом ширшої картини.
Reputation Management у нашому розумінні – це не «видалити все погане». Це часто неможливо, неетично і тільки підсилює проблему. Ми спершу фіксуємо, що саме ChatGPT, Gemini, Perplexity, Claude і Google AI Overviews кажуть про бренд. Потім дивимося, які джерела могли це сформувати: фактична помилка, репутаційний перекіс, брак джерел чи застарілий source layer. Далі будуємо нові нейтральні джерела – Wikipedia/Wikidata, Reddit/Quora, медіа, LLM-readable hub, structured data – і повторно перевіряємо відповіді через 2, 4, 6 і 12 тижнів.
Якщо AI робить «vibe check», ми не малюємо бренду фальшиву усмішку. Ми даємо системі більше якісних джерел, щоб вона бачила не один старий скандал, а реальну пропорцію.
Як працює Native Organic Promotion на Reddit?
Нормальна Reddit-стратегія починається не з постингу, а з питання: чи має бренд право бути в цій розмові?
Reddit дуже швидко карає рекламу, замасковану під «думку користувача». Тому наш принцип простий: жодних ботів, fake accounts, куплених голосів і «20 акаунтів накидали апвотів». Це не growth hack, а цифровий слід із запахом паленої пластмаси.
Механіка виглядає так. Спершу AI та community audit: як моделі описують бренд і конкурентів, у яких subreddits реально обговорюють категорію, де є buyer intent, а де бренд буде чужорідним тілом. Потім шукаємо buyer questions: «alternatives to HubSpot for small e-commerce», «best furniture delivery Kyiv», «which mattress brand is actually durable», «what CRM works with Shopify and offline retail». Тему диктує не бренд, а користувач.
Далі створюється корисний внесок. Головний тест: якщо прибрати назву бренду, відповідь усе одно має бути цінною. Наприклад, не «наш сервіс найкращий», а «ось 7 критеріїв вибору CRM для магазину з 5,000 SKU, 3 складами й поверненнями через Нову пошту». У частині кейсів працює disclosed expert participation: спеціаліст відкрито пояснює категорію, порівнює підходи, відповідає на заперечення.
Після публікації Reddit не можна кидати як білборд. Треба відповідати, уточнювати, визнавати обмеження продукту.
Типовий цикл – 90 днів: baseline audit, subreddit fit, контент-стратегія, 2-4 тижні тестового юніту від €980 або місячний ритм від €1,500, а далі tracking: чи з’являється бренд у AI-відповідях і як змінюється share of voice.
Чому українським e-commerce компаніям часто видаляють Wikipedia-сторінки?
Бо вони плутають Wikipedia з корпоративним блогом. Компанія дає контент-менеджеру сайт, презентацію, пару PR-публікацій і просить «зробити сторінку». Той пише звичний текст: «лідер ринку», «інноваційний сервіс», «широкий асортимент», «клієнтоорієнтований підхід». Для сайту це норма. Для Wikipedia – червона ганчірка.
Головні помилки: рекламний стиль замість енциклопедичного; плутання популярності зі значущістю; спроба довести notability пресрелізами, власним сайтом, каталогами, партнерськими матеріалами чи інтерв’ю «про себе»; нерозкритий conflict of interest; створення сторінки зарано; відсутність підтримки після публікації.
Wikipedia цікавить не те, що компанія говорить про себе, а те, що про неї вже сказали незалежні, надійні, вторинні джерела. Тому перед публікацією ми проганяємо джерела через матрицю: незалежне медіапокриття, публічний слід компанії, історія сторінки у Wikipedia, ризики COI і deletion history. Якщо переважає червоне світло, ми не тягнемо клієнта в завідомо слабку публікацію, а пропонуємо маршрут: Wikidata, Simple English Wikipedia, локальна мовна версія, Reddit/Quora, медіа або згадки в наявних статтях.
Чи може середній інтернет-магазин або український B2B-сервіс мати власну сторінку у Wikipedia?
Може, але не «просто тому, що бізнес хороший». Wikipedia – не каталог компаній і не полиця з бейджами для маркетингу. Для окремої сторінки потрібна енциклопедична значущість: significant coverage у reliable, independent, secondary sources. Тобто не випадкова згадка в новині, а достатньо глибоке висвітлення, яке дозволяє написати нейтральну статтю без оригінального дослідження.
Зазвичай не працюють пресрелізи, статті «на правах реклами», власний блог, сторінки на маркетплейсах,каталоги, короткі новини про запуск, афілійовані «топ-10 магазинів» і інтерв’ю, де засновник просто сам себе описує.
Може працювати глибокий профіль у незалежному медіа, аналітика ринку, де компанія є важливим кейсом, галузевий звіт, розслідування, публікації про M&A, інвестиції, міжнародну експансію, регуляторний статус, технологічну інновацію або незалежний редакційний огляд продукту.
Для багатьох українських e-commerce брендів English Wikipedia ще зарано. Але може бути реалістичний шлях через локальну мовну версію, Wikidata від €550, Simple English Wikipedia або спершу через source-base building. Англійська сторінка для компанії стартує від €1,930, але головне питання не в ціні, а в тому, чи витримують джерела перевірку.
Якщо компанія ще не «доросла» до окремої сторінки, як працює інтеграція згадок у загальні статті?
Це не «вставити лінк у Wikipedia». Такий підхід швидко виглядає як спам. Правильна логіка інша: якщо бренд, його дослідження або незалежне висвітлення реально додає енциклопедичну цінність до теми, це може стати джерелом чи прикладом у ширшій статті.
Наприклад, меблевий бренд публікує якісне дослідження про доставку великогабаритних товарів в Україні – воно потенційно може бути джерелом у статті про логістику. Маркетплейс має відкриті дані про поведінку продавців – це може працювати для статті про marketplaces. B2B-сервіс має незалежне висвітлення як кейс автоматизації складу – це може бути згадкою у ширшому контексті warehouse automation.
SEO/SERM-ефект тут непрямий, але цінний: бренд з’являється в high-trust source environment, посилює entity footprint, додає source density для AI-відповідей, стабілізує репутаційну видачу і збільшує шанс, що AI згадає його не лише через власний сайт.
Вікі-війни і захист репутації: що робити, якщо конкуренти правлять сторінку або номінують її на видалення?
Перше – не панікувати й не відкочувати все підряд із корпоративного акаунта. Wikipedia-сторінка не належить бренду. Кожну зміну треба оцінювати редакційно: це вандалізм чи фактична помилка? Негатив підкріплений джерелом? Чи є порушення NPOV? Чи створено undue weight? Чи має deletion nomination реальну підставу?
Більшість змін у Wikipedia не є кризою: боти, технічні правки, категорії, дрібна граматика. Але серед цього шуму іноді ховається одна справді небезпечна зміна – вилучили ключове джерело, додали токсичний абзац, поставили notability tag, відкрили deletion discussion. Перші 1-2 тижні після публікації особливо важливі через New Page Patrol, а після 90-го дня часто починається тихий «дрейф»: сторінку вже ніхто не дивиться щодня, і дрібні неточності осідають як пил у серверній.
У WikiBusines є чотири рівні Annual Support:
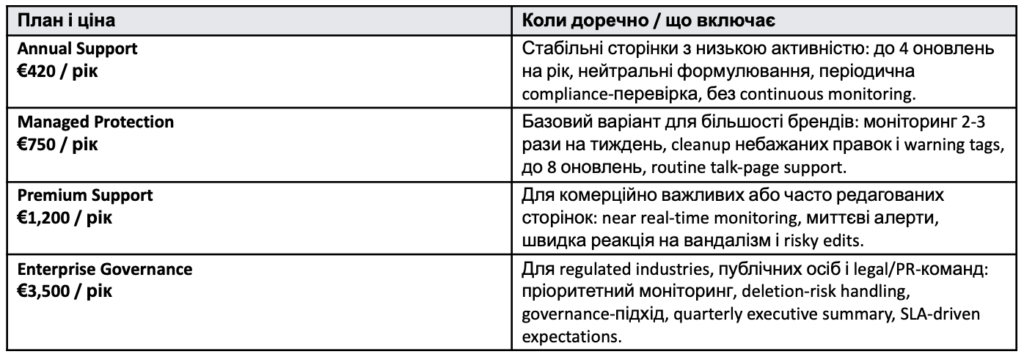
Premium і Enterprise включають WikiMonitoring toolset: email і Telegram alerts, anomaly flags для сплесків правок, IP-кластерів, підозрілих джерел і вилучених цитувань. Annual Support – це не обіцянка, що ніхто нічого не напише. Це обіцянка, що критична зміна не висітиме місяцями, поки її випадково не побачить клієнт, журналіст чи інвестор.
Яких результатів може очікувати e-commerce від Reddit і Wikipedia?
Їх не можна міряти однаково. Reddit ближчий до performance і demand shaping, особливо там, де люди довго порівнюють перед покупкою. Але last-click часто недооцінює Reddit, бо рішення визріває в треді за тижні до
фінального кліку. За даними Reddit/Fospha, лише 3% revenue influence Reddit фіксується last-click attribution, а коли в модель додали Amazon-покупки, ROAS зріс на 82%.
Це добре показує природу каналу: Reddit часто не останній клік, а місце, де людина перестає сумніватися.
Для organic-кампаній ми дивимося не тільки на продажі. KPI можуть бути такими: згадки бренду в релевантних тредах, share of voice, upvote ratio, sentiment, referral traffic, branded search lift, закриті buyer objections, цитування тредів у ChatGPT / Perplexity / Google AI Overviews.
Wikipedia – інший тип активу. Це trust asset, а не лідогенератор на завтра. Вона впливає на due diligence, procurement, журналістські та інвесторські перевірки, Knowledge Graph, AI-відповіді й міжнародну легітимність.
Просте правило: якщо потрібні продажі за два тижні – це ads, email, marketplace і SEO-лендинги.
Якщо будуєте бренд на роки й хочете, щоб AI описував вас коректно, Wikipedia, Wikidata, Reddit і Quora стають частиною інфраструктури. Реклама купує увагу. Ці платформи будують довіру, яку потім підхоплюють люди, Google і AI.
Чи є експрес-аудит, щоб власник побачив, що AI-моделі «говорять» про його компанію?
Так. Базовий формат – безкоштовний AI Visibility Audit. Протягом 48 годин ми показуємо, що ChatGPT, Gemini іPerplexity кажуть про бренд сьогодні, які джерела стоять за відповідями і де найбільші leverage gaps. Для глибшої діагностики є платний аудит і стратегія від €490.
Ми тестуємо реальні запити покупців: «best [category] company», «is [brand] reliable», «alternatives to [competitor]», «where to buy [product] in [city]». Дивимося, чи згадується бренд, чи згадуються конкуренти, які джерела цитуються, чи є старий негатив, плутанина, порожнеча у Wikidata, слабкий Reddit/Quora footprint або проблеми з Wikipedia readiness.
Для власника це часто холодний душ. Він думає: «у нас нормальний сайт і маркетинг», а ChatGPT радить трьох конкурентів, Perplexity цитує старий Reddit-тред, Gemini не розуміє, чим компанія займається, а Google AI Overview бере дані з випадкового агрегатора.
Новий репутаційний ризик полягає не лише в тому, що про вас можуть погано написати. Ризик у тому, що AI вже сформував відповідь про вас – просто ви її ще не бачили.
Ірина Маслова, Tovar.media












